


Introduction
Due to the availability of large-scale datasets and affordable computing resources, the field of machine learning has witnessed rapid progress over the past decade. Practical applications can be found in everyday life, e.g., targeted advertising in online shopping and recommender systems in music streaming services. With the widespread adoption of techniques such as facial recognition and person re-identification, the concern over security issues can not be overemphasized. While service providers collect and process sensitive information from end-users, perpetrators might misuse personal data and compromise user privacy.
In parallel with improving the overall performance of machine learning models, significant efforts have been put into understanding their vulnerabilities. In this blog, I outline four types of attacks that are predominant in the literature: adversarial example attack, membership inference attack, model extraction attack, and model inversion attack.
Adversarial Example Attack
In adversarial example attacks, an adversary manipulates input data slightly so that a human may not observe the changes while the prediction generated by a model is distorted (see [1]). Figure 1 visualizes the scenario of adversarial example attack in . The TensorFlow Camera Demo App classifies the clean image (b) correctly, while the predictions on the adversarial images~(c)~and~(d)~are wrong. Note that the difference between the clean image and adversarial images is subtle for a human observer.

Figure 1. Illustration of adversarial example attack in [1].
Such adversarial example attacks pose security concerns in the sense that machine learning models produce undesirable predictions. For example, a suspect in a crime scene may wear certain clothes so that the facial recognition system would fail to detect and identify the person of interest.
Membership Inference Attack
In membership inference attacks, an adversary is interested in identifying whether a specific sample is included in a model’s training set. Figure 2 shows the pipeline of membership inference attack in [2]. On the one hand, the target model generates the prediction on the data record, and probabilities of each class are returned. On the other hand, the attack model is trained on the ground truth label and the prediction label, and it behaves differently depending on whether the data record is used for training the target model.
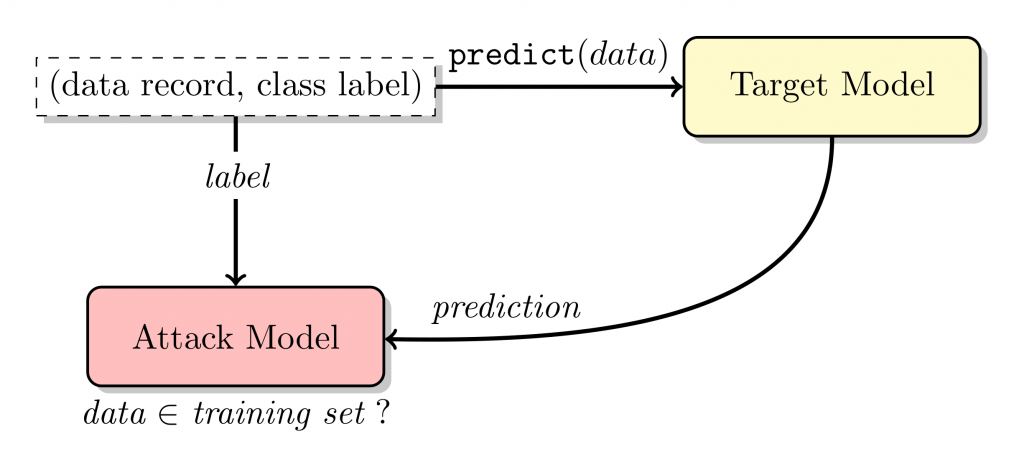
Figure 2. Illustration of membership inference attack in [2].
Given data of a specific subject, knowing that the data is part of a machine learning model’s training set implies information leakage. More concretely, one may predict whether a particular patient has a disease, given a model which determines the appropriate medication dosage for a disease along with the clinical record of the patient.
Model Extraction Attack
In model extraction attacks, an adversary has black-box access to a target model, and the primary purpose is to duplicate the functionality of the target model. Figure 3 demonstrates the diagram of model extraction attack in [3]. The data owner trains an original model on a proprietary dataset. The adversary receives predictions on queries and trains another model which approximates the original model.
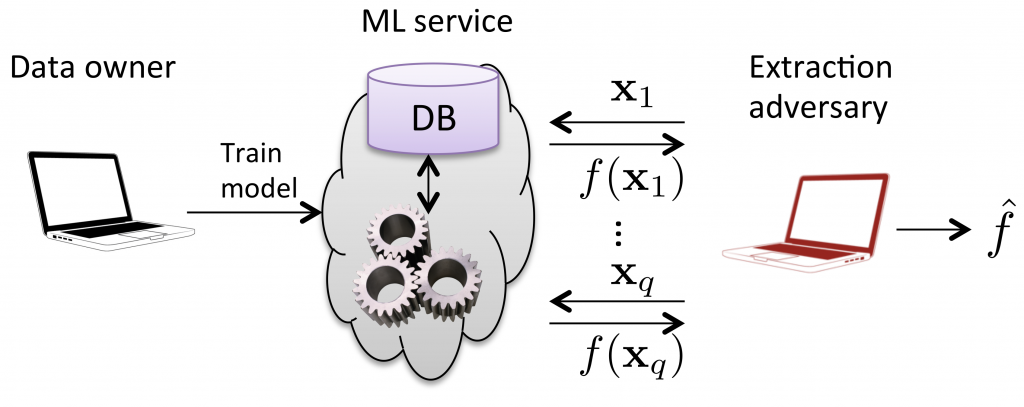
Figure 3. Illustration of model extraction attack in [3].
Developing machine learning models requires substantial efforts to collect/clean the dataset and optimize/validate the models. Model extraction attacks provide a way to pirate models that might be the intellectual property of service providers. This is a severe problem since many giant technology companies offer ”machine learning as a service”, in which anyone could get predictions of models via an easy-to-use API at a low cost.
Model Inversion Attack
In model inversion attacks, an adversary intends to infer sensitive input data from a released model. Figure 4 visualizes the outcome of model inversion attack in [4]. The image on the right is selected from the training images of a person. An attacker could recover the left image using only the confidence scores generated by a facial recognition model. It is evident that a significant amount of detail is visible in the generated image.

Figure 4. Illustration of model inversion attack in [4].
Model inversion attacks aim to sniff sensitive information of participants in a training set. It is inherently different from membership inference attacks, i.e., an adversary needs to reconstruct the training samples rather than creating a binary classifier. In a typical scenario, a machine learning model is trained on a large amount of data collected from specific individuals. Once the model is released for public use, an adversary can recover sensitive information of those individuals with prior knowledge. The vulnerability to model inversion attacks is unavoidable for models with high predictive power.
Conclusion
Are machine learning models vulnerable? Definitely, yes. Exploiting the vulnerabilities of machine learning models is an active research topic, and new attack/defense methods are proposed by researchers every now and then. Even though it might be infeasible to devise a vulnerability-free model at the moment, practitioners are advised to investigate such vulnerabilities before deploying machine learning models into production. It helps in preventing data breaches and consolidating information security.
References
[1] Kurakin, Alexey, Ian Goodfellow, and Samy Bengio. ”Adversarial examples in the physical world.” (2016).
[2] Shokri, Reza, et al. ”Membership inference attacks against machine learning models.” 2017 IEEE Symposium on Security and Privacy (SP). IEEE, 2017.
[3] Tramèr, Florian, et al. ”Stealing machine learning models via prediction apis.” 25th {USENIX} Security Symposium ({USENIX} Security 16). 2016.
[4] Fredrikson, Matt, Somesh Jha, and Thomas Ristenpart. ”Model inversion attacks that exploit confidence information and basic countermeasures.” Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. 2015.
Blog post by Xingyang Ni