
The second winter school of the APROPOS project took place at the IBM Europe Research Center in Zurich, Switzerland, and was organized by the University of Bologna (Italy). Presentations covered topics about precision tuning, transprecision, and quantization computing at the compiler and architectural levels, as well as sparsity in Deep Learning (DL) and Open-Source research. In this post, we summarize the presentations and links related to the projects for further information.
A detailed schedule of the training week is available in a previous blog post [1].

1st Day (14 February):
The event started with an introduction to IBM and its research area. The talk started with the IBM’s history and its achievements in scientific progress. IBM members were awarded the Noble Prize in 1986 and 1987—also, the Kavli Prize in 2016. The main research areas of this center are Quantum Computing, Artificial Intelligent (AI), and Hybrid Cloud. More details can be found at [2].
“Low-power multi-core solutions for approximation” by Luca Benini (UNIBO)
Luca Benini started his talk by explaining the challenges of Machine Learning (ML) for embedded devices. He introduced Tiny Machine Learning (TinyML), a field of ML that focuses on developing low-power, low-cost, and small-size machine learning models that can run on microcontrollers and other embedded devices. Afterward, he introduced RISC-V processors and mentioned that one of the key advantages of RISC-V is its open-source nature, which allows anyone to use, modify, or distribute the Instruction Set Architecture (ISA) without any licensing fees or restrictions. Therefore, there is a possibility to add custom implementations by using the free opcodes in RISC-V.
He explained that Parallel Ultra Low Power (PULP) [3] is an open-source multi-core platform for designing energy-efficient, parallel computing systems [4]. It is based on the RISC-V ISA and includes various hardware and software components to support various parallel processing applications.
In addition to the processor cores, the PULP platform consists of a range of other hardware components, such as memory controllers, communication interfaces, and accelerators, designed to support efficient parallel processing.
He also mentioned some extensions added to RISC-V ISA in Xpulp. After that, he provided some experimental results on Xpulp Extensions Performance. You can find all features together in VEGA, an extreme edge IoT processor. More details are available in their recent paper [5].
“Heterogeneous accelerators for AC/TC” by Gianna Paulin (ETH)
Gianna Paulin explained Hardware Processing Engines (HWPEs) and why the accelerators are needed besides the software-oriented platforms. HWPEs are special-purpose, memory-coupled accelerators that can be inserted in the SoC or cluster of a PULP system to amplify its performance and energy efficiency in particular tasks.
The central core of her talk was about multiple hardware accelerators for approximate or transprecision computing that their group developed in ETH and UNIBO. She also discussed integrating these accelerators into the PULP platform, the required interconnect infrastructure, and memory access. The following hardware accelerators were introduced in her presentation [6]. XNE: Binary Neural Network Inference, RBE: Convolutions, flexible precision for weights and activations [7], and RedMulE: floating-point GEMM accelerator [8].
The mentioned accelerators focus on low-power applications: near-sensor processing, nano-UAVs, etc. Finally, Gianna presented some high-performance platforms such as Snitch core & FREP [9], HERO [10], and Occamy [11].
“Compiler-based precision tuning” by Giovanni Agosta (POLIMI)
Approximate computing can be applied to different levels of implementation. Giovanni Agosta explained how the compilers could be optimized for approximate computing. The ideal compiler should be able to find the hot spots of the program that can obtain speed-up after converting the data types to less precise ones. Some milestones to reach this ability include hot spot detection, value range analysis, code manipulation, and validation. Giovanni’s team tried solving some challenges in their developed suite of compiler plugins, TAFFO, that can automatically tune the computation precision. He explained the features and applications of TAFFO. A hands-on tutorial on TAFFO realized by our ESR Lev Denisov can be found here [12].
TAFFO also supports parallel computing Application Programming Interfaces (APIs) such as Pthread, OpenCL, CUDA, &SYCL, MPI, and OpenMP with some restrictions. This area still has many adventures to explore, including dynamic memory allocation, empowering artificial intelligence, etc., that they are trying to solve in their future work.
Ultimately, he explained two case studies explored by TAFFO: Field-Oriented Control (FOC) [13] and Fall Detection [14].
“Transprecision computing: State-of-the-art and available tools” by Giuseppe Tagliavini (UNIBO)
Giuseppe Tagliavini started his presentation by introducing transprecision and smallFloats. Consequently, he mentioned some available transprecision computing tools. For each tool, he showed the advantages and disadvantages and how to use it with an example.
- MPFR [15] is a C library based on GNU Multi-Precision Library (GMP). They provided a C++ interface wrapper called MPREAL [16] to use MPFR. The library is open source; All the required libraries are included in a single header (mpreal.h).
- Flexfloat is an emulation library for arbitrary floating-point types with full support for IEEE 754 concepts and a performance-efficient approach. Flexfloat is implemented in C and is available as an open-source library [17].
- FloatX [18] is a Header-only C++ library for emulating low-precision floating point types, and you can use this library on CUDA.
He also reviewed Program Round-off Error Certifier via Static Analysis (PRECiSA). PRECiSA [19] is a fully automatic analyzer for estimating floating-point valued functional expression round-off errors. After that, he mentioned the SmartFPTuner+ library, which uses AI for precision tuning. SmartFPTuner+ is based on an ML algorithm trained to predict different floating-point data types’ numerical errors and performance for a given computation [20]. It combines ML and optimization using a methodology called Empirical Model Learning (EML).
In the second part of his talk, Giuseppe introduced PULP-NN [21]. PULP-NN is a multi-core computing library for Quantized Neural Network (QNN) inference on PULP clusters of RISC-V-based processors. It includes optimized kernels such as convolution, matrix multiplication, pooling, normalization, and other common state-of-the-art QNN kernels. It fully exploits the Xpulp ISA extension (e.g., post–incrementing load/store instruction, hardware loops) and the cluster’s parallelism to achieve high performance and energy efficiency on PULP-based devices. It has been tested on GWT GAP8 [22]. It supports the vectorization capabilities of PULP RI5CY/CV32E40P cores and tries to transform all linear operators into a Generalized Matrix Multiplication (GEMM) form.
Finally, he explained POSIT data representation and Deep PeNSieve. Deep PeNSieve is a framework to perform both training and inference of DNNs employing the Posit Number System [23].
2nd Day (15 February):
“Transprecision floating point units” by Luca Bertaccini (ETH)
Luca Bertaccini explained Transprecision Computing. In many programs, different parts of the computation chain may require different levels of precision depending on their specific requirements. In transprecision computing, different parts of the computation progress use different precision levels to balance accuracy and efficiency.
Luca mentioned several benefits of using SmallFloats (e.g., Float16, Bfloat16, and Float8) on hardware, such as reduced memory footprint and Single Instruction, Multiple Data (SIMD) vectorizations.
The figure below shows low-precision formats.
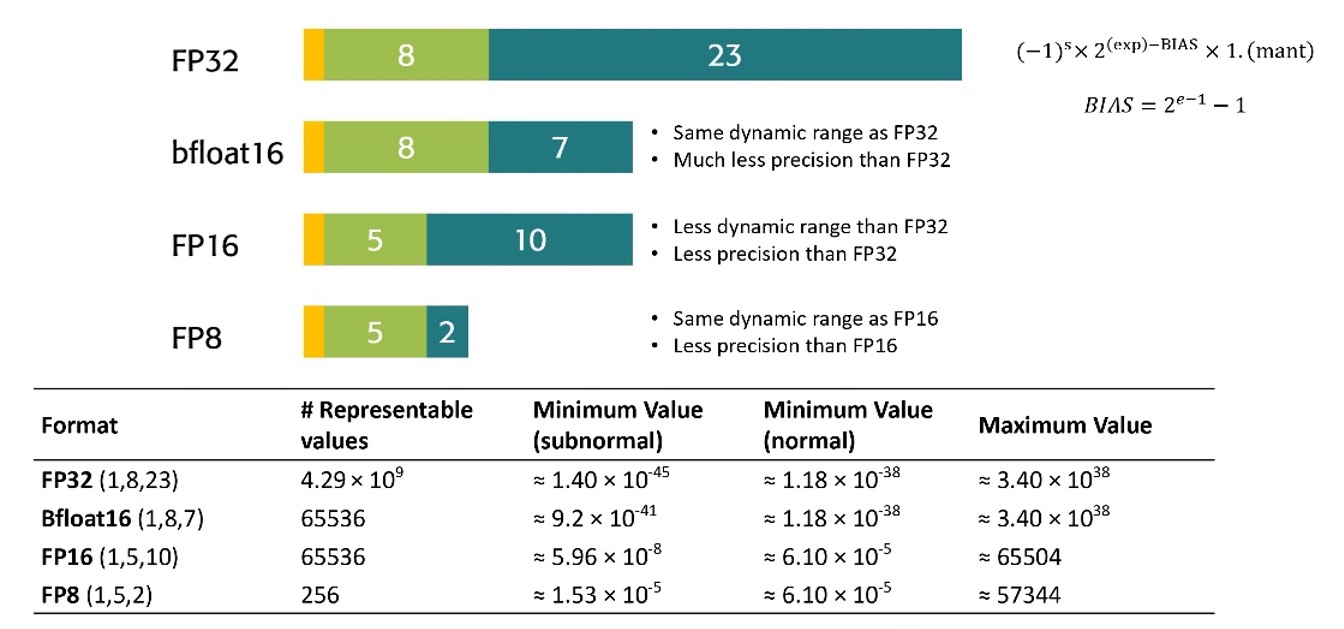
Luca presented an open-source Transprecision Floating Point Unit (CVFPU) [24]. CVFPU is designed to improve the energy efficiency and performance of floating-point operations in embedded systems by supporting smaller floating-point formats.tectures. CVFPU supports these operations: Addition/Subtraction, Multiplication, Fused Multiply-Add (FMA) in four flavors (fmadd, fmsub, fnmadd, fnmsub), Division, Square root, Minimum/Maximum, Comparisons, Sign-Injections (copy, abs, negate, copySign, etc.), Conversions among all supported FP formats, Conversions between FP formats and integers (signed & unsigned) and vice versa, Classification. Multi-format FMA operations (i.e., multiplication in one format, accumulation in another) are optionally supported in their unit. Finally, he presented their experimental results to evaluate CVFPU.
“Hardware design for approximate computing” by Georgios Karakonstantis (QUB)
Georgios Karakonstantis talked about approximation at different hardware levels of implementation. According to equation 1, on-chip dynamic power consumption depends on frequency (F), switching activity (a), and square of the supply voltage . Therefore, Dynamic Voltage and Frequency Scaling (DVFS) is one of the most effective methods to reduce power consumption. Decreasing the voltage and approximation can cause malfunctions and timing errors, so Georgios explained methods for error prediction and detection [25].
![]() (Equation 1)
(Equation 1)
In the end, he explained his works on approximation at the architectural level. One of his latest works is about energy-efficient Fast Fourier Transform (FFT) [26]. Since FFT is one of the most commonly used algorithms in signal processing, this work can significantly impact different applications implemented on low-power devices.
Their team also worked on applying approximation techniques such as optimization and pruning to algorithms. One used case is the detection of sinus arrhythmia [27].
“Sparsity in Deep Learning” by Torsten Hoefler (ETH)
Torsten Hoefler started his talk with the evolution of Machine Learning and its improvement speed. Therefore, on the one hand, the necessity of high-performance computing and supercomputers is vital. On the other hand, machine learning models are overgrowing, so there is a need to compress and optimize the models. Sparcification is one of the optimization methods that can be divided into two main branches Model Sparsity and Ephermal Sparsity. Detailed definitions and classifications are found in one of their publications [28].
In the end, he explained some works on sparse Convolutional Neural Networks (CNNs) and sparsified transformers. Besides the software side developments, various hardware accelerators are also designed for sparse deep neural networks.
More details about their research can be found at [29].
“Exploiting adjustable precision in iterative numerical computations” by Enrique Quintana Orti (UPV)
Enrique Quintana Orti also started his talk by explaining floating points and mixed precision computing [30]. He mentioned that “transprecision computing does not imply reduced precision at the application level, even though it is also possible to exploit application-level softening of precision requirements for extra benefits.”
He also explained direct and iterative methods applied to linear systems and how mixed precision would work on these methods. For example, Jacobi [31] and GMRES are iterative methods that can benefit from mixed precision [32], [33].
“Transprecision Communication & FPGA DevOps” by Dionysios Diamantopoulos (IBM)
Dionysios Diamantopoulos explained their team’s research on trasnprecision communication. Communication is challenging in heterogeneous distributed systems consisting of CPU, FPGA, and Accelerators. A message sent by the source system should be serialized in the communication channel and deserialized at the destination. Also, transferring transprecision data types affect the goodput. So, they proposed a messaging framework for trasnprecision hardware accelerators that efficiently serialize and deserialize transprecision data types [34].
More details about his research can be found in [35].
3rd Day (16 February):
“The importance of research in open source business” by Paolo Savini (EMBECOSM)
Paolo Savini started his presentation with an overview of compilers’ evolution and their working criteria in Embecosm company. Their core services are Compiler Tool Chain Development, Hardware Modeling, Embedded Operating Systems, and Open-Source Tool Support.
Embench is an embedded benchmark suite Embecosm is developing as an open-source project. The project is ongoing, and other researchers can collaborate with them to develop the benchmarks for floating point Digital Signal Processing (DSP) algorithms.
More details about Embecosm can be found in [36].
“Quantization techniques for IoT computing at the edge” by Manuele Rusci (KU LEUVEN)
Manue Rusci started his talk by discussing the requirements and challenges of implementing AI on edge devices. PULP-NN is a multicore computing library for Quantized Neural Networks (QNN) inference on PULP. Post Training Quantization (PTQ) and Quantization-Aware Training (QAT) are two methods for quantizing DNNs. He compared these two methods’ pros and cons. Their group has done multiple projects utilizing both methods. Plate Detection and Recognition [37] is one of the projects on GAP8. The project implements an image-based deep-learning pipeline to detect license plates and read the registration number.
Next, he explained GAP9 and his recent project on this platform. The project was Mixed-Precision Speech Enhancement on multi-core MicroController Units (MCUs) [38]. This paper presents an optimized methodology to design and deploy Speech Enhancement (SE) algorithms based on Recurrent Neural Networks (RNNs) on a state-of-the-art MCU with 1+8 general-purpose RISC-V cores.
Finally, he explained Enabling perception on Nano-Robots [39], [40], and PULP-TrainLib [41] as two case studies on MCUs. PULP-TrainLib is the first DNN training library for the PULP platform.
Acronyms
- DL: Deep Learning
- AI: Artificial Intelligent
- ML: Machine Learning
- TinyML: Tiny Machine Learning
- ISA: Instruction Set Architecture
- PULP: Parallel Ultra Low Power
- HWPEs: Hardware Processing Engines
- PRECiSA: Program Round-off Error Certifier via Static Analysis
- QNN: Quantized Neural Network
- GEMM: Generalized Matrix Multiplication
- FP: Floating Point
- FMA: Fused Multiply-Add
- FFT: Fast Fourier Transform
- MCU: MicroController Unit
References
- https://projects.tuni.fi/apropos/news/apropos-winter-school-in-zurich/
- https://www.zurich.ibm.com/
- https://pulp-platform.org/
- https://github.com/pulp-platform/
- Rossi et al., “Vega: A ten-core SoC for IoT endnodes with DNN acceleration and cognitive wake-up from MRAM-based state-retentive sleep mode,” IEEE Journal of Solid-State Circuits, vol. 57, no. 1, pp. 127-139, 2021.
- https://hwpe-doc.readthedocs.io/en/latest/papers.html
- https://github.com/pulp-platform/rbe
- https://github.com/pulp-platform/redmule
- https://ieeexplore.ieee.org/abstract/document/9216552
- https://arxiv.org/abs/2201.03861
- com/pulp-platform/snitch
- https://projects.tuni.fi/apropos/news/taffo/
- Magnani, D. Cattaneo, M. Chiari, and G. Agosta, “The impact of precision tuning on embedded systems performance: A case study on field-oriented control,” in 12th Workshop on Parallel Programming and Run-Time Management Techniques for Many-Core Architectures and 10th Workshop on Design Tools and Architectures for Multi-core Embedded Computing Platforms (PARMA-DITAM 2021), 2021: Schloss Dagstuhl-Leibniz-Zentrum für Informatik.
- Fossati, D. Cattaneo, M. Chiari, S. Cherubin, and G. Agosta, “Automated precision tuning in activity classification systems: A case study,” in Proceedings of the 11th workshop on parallel programming and run-time management techniques for many-core architectures/9th workshop on design tools and architectures for multi-core embedded computing platforms, 2020, pp. 1-6.
- https://www.mpfr.org
- https://github.com/advanpix/mpreal
- https://github.com/oprecomp/flexfloat
- https://github.com/oprecomp/floatx
- http://precisa.nianet.org/
- https://github.com/oprecomp/StaticFPTuner
- https://github.com/pulp-platform/pulp-nn
- https://greenwaves-technologies.com/wp-content/uploads/2021/04/Product-Brief-GAP8-V1_9.pdf
- http://www.johngustafson.net/pdfs/BeatingFloatingPoint.pdf
- https://github.com/openhwgroup/cvfpu
- Tsiokanos, G. Papadimitriou, D. Gizopoulos, and G. Karakonstantis, “Hardware Level Approximations,” in Approximate Computing Techniques: From Component-to Application-Level: Springer, 2022, pp. 43-79.
- Eleftheriadis and G. Karakonstantis, “Energy-efficient fast fourier transform for real-valued applications,” IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 69, no. 5, pp. 2458-2462, 2022.
- Karakonstantis, A. Sankaranarayanan, M. M. Sabry, D. Atienza, and A. Burg, “A quality-scalable and energy-efficient approach for spectral analysis of heart rate variability,” in 2014 Design, Automation & Test in Europe Conference & Exhibition (DATE), 2014: IEEE, pp. 1-6.
- Hoefler, D. Alistarh, T. Ben-Nun, N. Dryden, and A. Peste, “Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks,” The Journal of Machine Learning Research, vol. 22, no. 1, pp. 10882-11005, 2021.
- https://www.youtube.com/@spcl
- J. Higham and T. Mary, “Mixed precision algorithms in numerical linear algebra,” Acta Numerica, vol. 31, pp. 347-414, 2022.
- Anzt, J. Dongarra, and E. S. Quintana-Ortí, “Adaptive precision solvers for sparse linear systems,” in Proceedings of the 3rd International Workshop on Energy Efficient Supercomputing, 2015, pp. 1-10.
- I. Aliaga, H. Anzt, T. Grützmacher, E. S. Quintana-Ortí, and A. E. Tomás, “Compressed basis GMRES on high-performance graphics processing units,” The International Journal of High Performance Computing Applications, p. 10943420221115140, 2022.
- Flegar, H. Anzt, T. Cojean, and E. S. Quintana-Orti, “Adaptive precision block-Jacobi for high performance preconditioning in the Ginkgo linear algebra software,” ACM Transactions on Mathematical Software (TOMS), vol. 47, no. 2, pp. 1-28, 2021.
- Diamantopoulos, M. Purandare, B. Ringlein, and C. Hagleitner, “Phryctoria: A messaging system for transprecision opencapi-attached fpga accelerators,” in 2020 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), 2020: IEEE, pp. 98-106.
- https://research.ibm.com/people/dionysios-diamantopoulos
- http://www.embecosm.com/
- https://github.com/GreenWaves-Technologies/licence_plate_recognition
- https://arxiv.org/abs/2210.07692
- https://arxiv.org/abs/2301.12175
- https://github.com/pulp-platform/pulp-dronet/tree/master/pulp-dronet-v2
- https://github.com/pulp-platform/pulp-trainlib


