
The popularity of the Internet of Things (IoT) and next-generation wireless networks calls for a greater distribution of small but high-performance and energy-efficient compute devices at the networks’ Edge. These devices must integrate hardware acceleration to meet the latency requirements of relevant use cases. Existing work has highlighted Coarse-Grained Reconfigurable Arrays (CGRAs), illustrated in Fig. 1, as suitable compute architectures for this purpose. However, like other modern hardware design, research and design space exploration into CGRAs is hindered by long development times needed for implementation in Hardware Description Language (HDL). In two new publications, we address this issue and describe our work towards a new flow, CGRAgen, for exploring CGRAs enriched with Approximate Computing (AxC) features. Being a work-in-progress, the flow has generic application and architecture modeling components, a simple mapping engine, and a hardware generation backend capable of producing HDL descriptions of Processing Elements (PE).
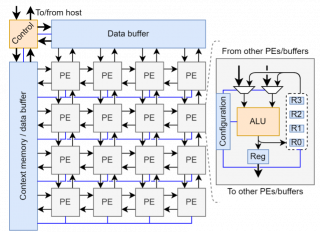
Figure 1 Illustration of a generic CGRA and one of its PEs. As shown, CGRAs feature a mesh array of (possibly heterogeneous) PEs whose internals and interconnects may be reconfigured at runtime with low overheads. Their flexibility renders them particularly suitable for the IoT domain.
In our first paper presented at the FPL 2023 PhD Forum, we describe the current state of CGRAgen and present some preliminary mapping results. We consider the flow’s four components and outline many directions for future work for each:
- The application modeling component needs a compiler-like tool for automatic extraction of Data Flow Graphs (DFGs) from source code written in C or C++. To support AxC, it also needs a significance analysis pass that assigns approximation modes to DFG nodes given quality constraints on individual outputs.
- The architecture modeling component offers many opportunities for extensions, including support for conditional execution by predication, parameterizable module sizes, and memory-related primitives. In accordance with the application modeling flow, architectures must also be able to model AxC techniques with guaranteed error characteristics.
- The mapping engine is currently based on integer linear programming and suffers from extremely long execution times even for small examples. We believe one or more heuristics can be applied to drastically reduce this while still achieving sufficiently efficient mappings.
- The hardware generation backend needs extensions following the architecture modeling capabilities of CGRAgen: first, it should be able to generate HDL descriptions of entire CGRAs; then, it should be able to generate architectures with predication and inter-PE data flow based on handshaking; and last, it should include a collection of inexact arithmetic units with pre-determined error characteristics.
In our second paper presented at the Euromicro DSD 2023 conference, we zoom in on the hardware generation backend capable of generating HDL descriptions of arbitrary PEs. The backend is closely linked to the flow’s architecture modeling component and utilizes the Chisel framework, instead of a manually written HDL generator, to construct hardware modules. The main novelty of our flow is its use of dynamically defined module I/O enabled by Scala’s lazy evaluation feature. No traditional HDL supports a similar feature! This initially led to an unexpected side effect: that I/O ports would be named depending on their connection context and not as requested by the user. We managed to resolve this using only built-in functionality of Chisel. We demonstrate the developed backend by modeling, generating, and synthesizing four popular PE architectures from the literature, illustrated in Fig. 2. The results of this experiment are available in the paper.

Figure 2 Block diagrams of the PEs used to demonstrate CGRAgen’s hardware generation backend: (a) ADRES, (b) CMA, (c) HyCUBE, and (d) RF-CGRA.
The full papers are in press and will be available in IEEE Xplore soon.
